
目前人工智能相关的课题极为的火爆,很多人不知道的该如何入手研究人工智能,本文为新手小白做了人工智能的介绍以及需要学习地相关课程推荐。
{kind=link}
参考课程:
人工智能的阶段
第一阶段:人工智能必备基础
1)python 基础教程(第三版)
2)数学之美(吴军,第三版)
3)利用python进行数据分析(python 实战,numpy,pandas)
第二阶段:机器学习
1)算法理论:统计学习方法、机器学习西瓜书、机器学习公式详解南瓜书
2)实战部分:阿里云天池大赛,赛点解析,机器学习篇
第三阶段:深度学习
1)神经网络与深度学习(深度学习原理)
2)动手学深度学习(动手部分,)
3)NLP:自然语言处理综述
4)计算机视觉算法与应用(CV计算机视觉)
第四阶段:论文
笔记
1.1 人工智能是什么
是什么:人工智能,是研究如何模拟、延伸并扩展人类智能的一门科学艺术
诞生背景:传统计算机编程可以解决"确定性问题”(最短距离计算, 偏微分方程求解…但对于不确定性问题(手写文字识别,垃圾邮件识别,听声辨人..难以解决)
主要目的:促使计算机像人一样,
1)会听:语音识别
2)会看:图像、文字识别
3)会说:语音合成,人机对话
4)会思考:人机对弈,定理证明
5)会学习:知识表示
6)会行动:机器人,自动驾驶
.
常见应用:推荐算法(知乎,浏览器等) ;手写体识别(邮件地址,发票) ;人脸识别(门禁) ;
安全中的应用:病毒文件检测;垃圾邮件检测;可疑域名检测;代码漏洞检测;异常行为......
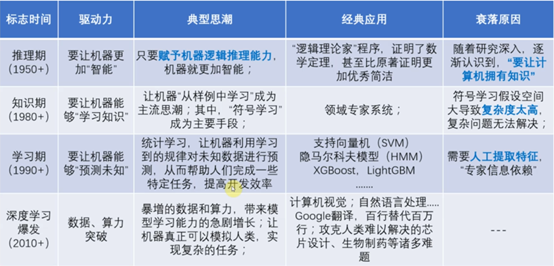
2.1 发展历史
.
基本概念
通过已知数据,去学习数据中蕴含的规律或者判断规则。
已知数据主要用作学习的素材,而学习的目的是推广,也就是把学到的规则应用到未来新的数据上并做出判断或者预测。
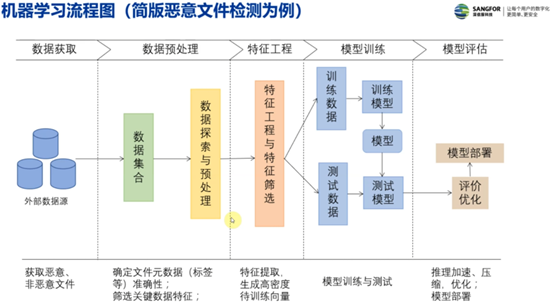
基本流程:
1)数据获取;
2)数据预处理;
3)特征工程z;
4)机器学习(模型训练);
5)模型评估(效果预测)
1)数据获取:自己采集;公开的数据集; (数据要具有代表性,广泛性)
2)数据预处理:归一化,离散化,去除共线性; (清洗数据,提高算法的效果)
3)特征工程:筛选显著特征,摒弃无用特征; (数据和特征工程决定了机器学习的结果上限,算法只是让模型尽可能逼近上限)
4)机器学习(模型训练):选模型;调参优化; (不同模型以及不同参数,在同一数据集效果预测差异显著)
5)模型评估(效果预测):过拟合,欠拟合;精准率(P),召回率(F); (高性能的模型对于数据具有较好的泛化性以及精确性)
.
3.1 机器学习算法分类
.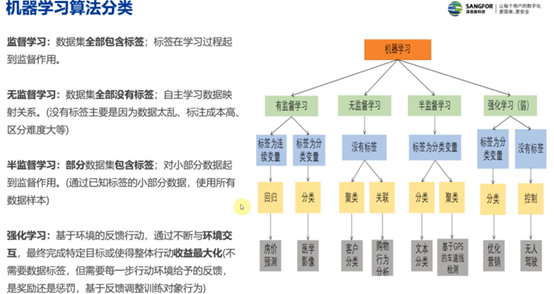
1)监督学习:数据集全部包含标签;标签在学习过程起到监督作用。
2)无监督学习:数据集全部没有标签;自主学习数据映射关系。(没有标签主要是因为数据太乱、标注成本高、区分难度大等)
3)半监督学习:部分数据集包含标签;对小部分数据起到监督作用。(通过已知标签的小部分数据,使用所有数据样本)
4)强化学习:基于环境的反馈行动,通过不断与环境交互,最终完成特定目标或使得整体行动收益最大化(不需要数据标签,但需要每一步行动环境给予的反馈,是奖励还是惩罚,基于反馈调整训练对象行为)
4.1 机器学习的适用场景
适用的场景:
1)有大量的经验数据或者特征可以借鉴;
2)应用的场景和条件简单清晰,比如下棋规则;
3)找寻最优解比较慢或者复杂的时候;
4)文本翻译等感知性问题;
不适用的场景:
1)缺乏数据训练系统,比如密码数据;
2)找寻最优解比较快的时候,比如信息查表;
3)逻辑证明,比如数学定理证明;
4)准确计算,比如微积分计算等
.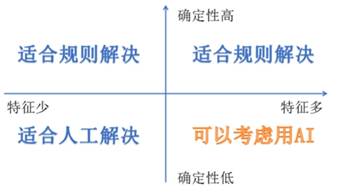
总的来说,机器学习适用于感知性的问题场景,而不适用于准确性的逻辑场景;适用于最优解获取复杂的问题场景,不适用于最优解获取简单的问题场景。
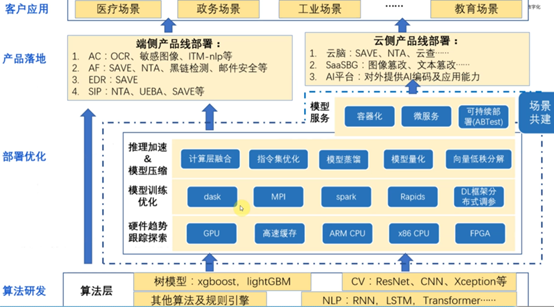
5.1 AI的落地过程
.
6.1 深度学习
机器学习与深度学习的区别?
DL VS ML,优劣比较:
1)端到端VS分阶段;学习能力更强,对特征工程要求更低
2)数据依赖: DL广泛的假设空间,依赖更广泛的样本
3)算力依赖: DL对计算能力要求极高,GPU必不可少
4)可解释性差:DL判断原理类似黑箱,经典的获得可解释性的方法,是通过ML模拟DL模型(蒸馏),进而获取可解释性;
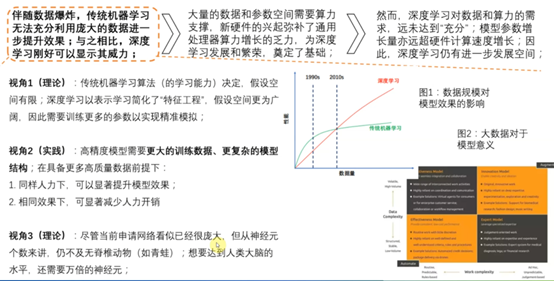
7.1 深度学习兴起的关键
数据+算力
.
.
7.1深度学习的经典应用范围,有哪些?
计算机视觉 (CV) ,自然语言处理(NLP)
1)CV方面:
常见的研究领域有:图像生成、图像识别、生成对抗网络、图像预处理、边缘检测、纹理分析、光流、图像分割、变化检测、跨域学习、小样本学习、域适应、半监督学习、无监督学习、自监督学习、注意力机制、图卷积网络、元学习、目标检测、异常检测等等。
2)NLP方面:
常见的研究领域有:词义消解、指代消解、语义角色标注、中文分词、问答系统、情感倾向性分析、推荐系统、阅读理解、知识图谱、隐喻机器处理、命名实体识别、关系挖掘、事件提取、文本分类、信息检索、信息抽取、机器翻译等。
常用的NLP模型有: RNN、Seq2Seq、Transformer、 GRU、GPT、LSTM、 Bert系列、Elmo、XLNet等 。
此评论已被作者删除。
回复删除