
为了处理字符,计算机必须对其进行表示。通常,字符和数字之间存在一套对应规则,即编码。
- ASCII 规定了字母和特殊字符的编码规则,仅需256位。在英语语境下,这256个字符构成了全部的文字系统。
- 汉字不同于英语,汉字是象形文字,无法通过组合构成。因此,汉字需要单独编码。GB2312 是一种编码规则,需要更多的位来标识汉字,例如两个字节、16位。该编码定义了不超过$2^{15}-1$的汉字字符量。
- Unicode 是一个将全球所有国家的文字进行编码的系统。它将世界上所有文字字符与数字对应起来,不会出现混乱,即使涉及不同语言的混合使用。
编码的应用
存在一个问题:若你向朋友发送一个文件,默认情况下使用Unicode编码,将所有文字转换为数字并存储。然而,每个数字都需要两个字节来表示。例如,发送数字1,使用ASCII 编码只需保存为 0000001(8位)即可。
但使用Unicode保存,需要保存为0000000000000001再发送给朋友。文件变大了,同时也浪费了空间。因为当发送ASCII时,只需朋友知道文件采用ASCII编码,就可以正确解读内容。
基于此,在存储和使用过程中出现了UTF-8编码。它简化了部分字符的存储,同时确保不会混淆内容。
UTF-8编码根据Unicode字符的数字大小将其编码为1-6个字节。常用的英文字母被编码成1个字节,汉字通常是3个字节。只有极少数的字符才会被编码成4-6个字节。若文本包含大量英文字符,使用UTF-8编码可节省空间。
值得注意的是,UTF-8编码的另一个好处是,ASCII编码实际上是UTF-8编码的一部分。因此,许多只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
使用过程
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件,节约存储成本。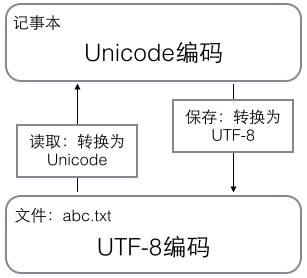
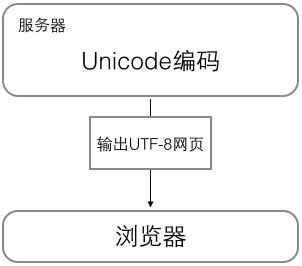
##实际应用
企业级的用法很很简单所有文件,指定编码的方式,打开方式也是指定方式。
文件创建、保存、和读取 都是用UTF-8 就可以通用全世界,你的程序文件就不问题。
案例:vscode 使用UTF-8 保存。你可以清晰啊看到对应标识。
主要你不是用论其八糟的啥子软件,就不会出现问题。

Tags
编程工具